1. Введение
Узел Mailhook на Нодуле — это инструмент, позволяющий создавать виртуальные email-адреса для приема писем.

Внутри узла вы можете обнаружить поле с адресами вебхуков и переключиться между dev и prod версиями.
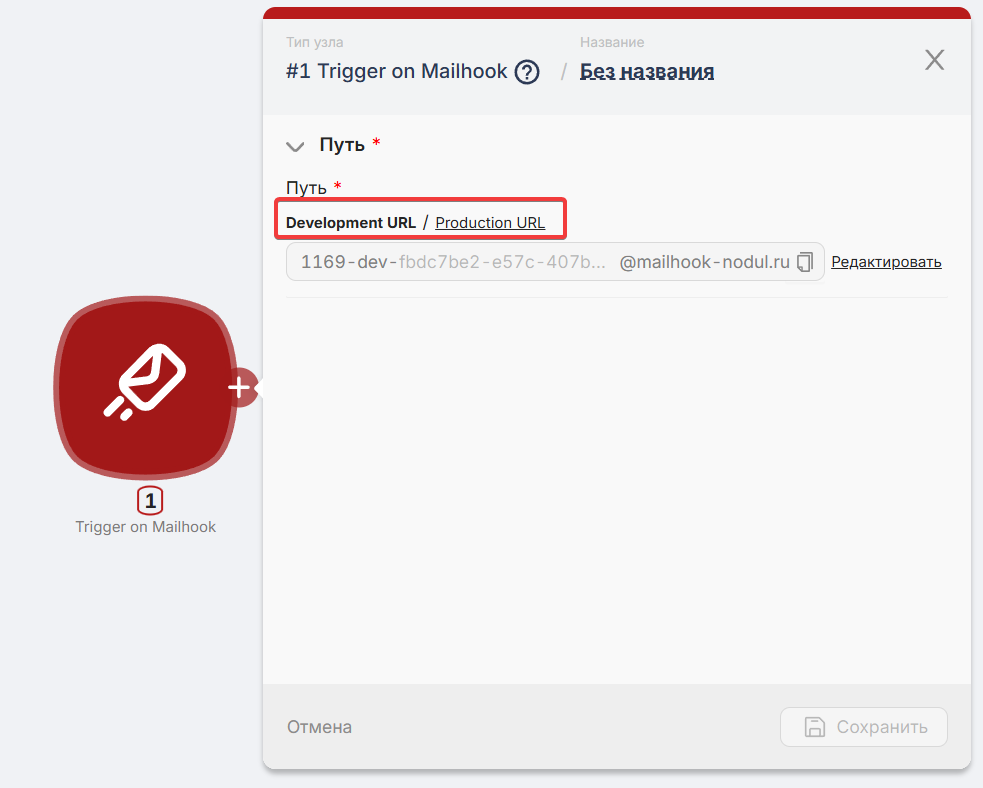
-
Dev-адрес существует исключительно для тестирования и отладки. Он готов принимать входящие данные только в момент, когда сценарий запущен вручную. Останавливает работу после первой активации — до следующего ручного запуска.
-
Prod-адрес вебхука — это адрес, который активируется после того, как вы развернете сценарий. Он будет готов принимать данные в любое время и используется для настоящих, автономных автоматизаций.
Примечание: По желанию вы можете редактировать адреса мейлхуков для вашего удобства.
2. Прием файла с помощью Mailhook
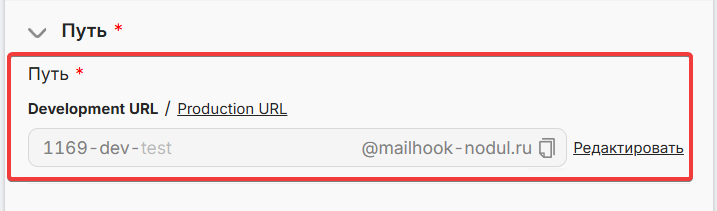
Чтобы получить файл через Mailhook, достаточно:
- Тестово запустить сценарий через “Запустить один раз”.
- Перейти в свой сервис и заполнить тестовое письмо.
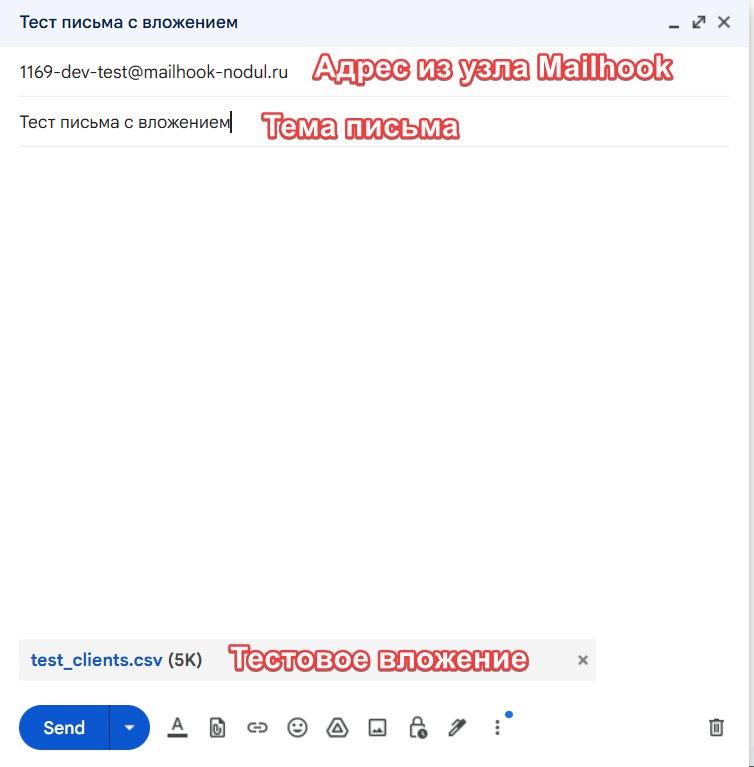
- Отправить письмо.
Спустя несколько секунд письмо отобразится в нашем сценарии.

Внутри сценария мы видим все данные полученного письма: данные отправителя, тело письма и вложения, которые находятся в разделе attachments. Также доступно превью файла, нажав на которое можно скачать вложение на свой ПК.
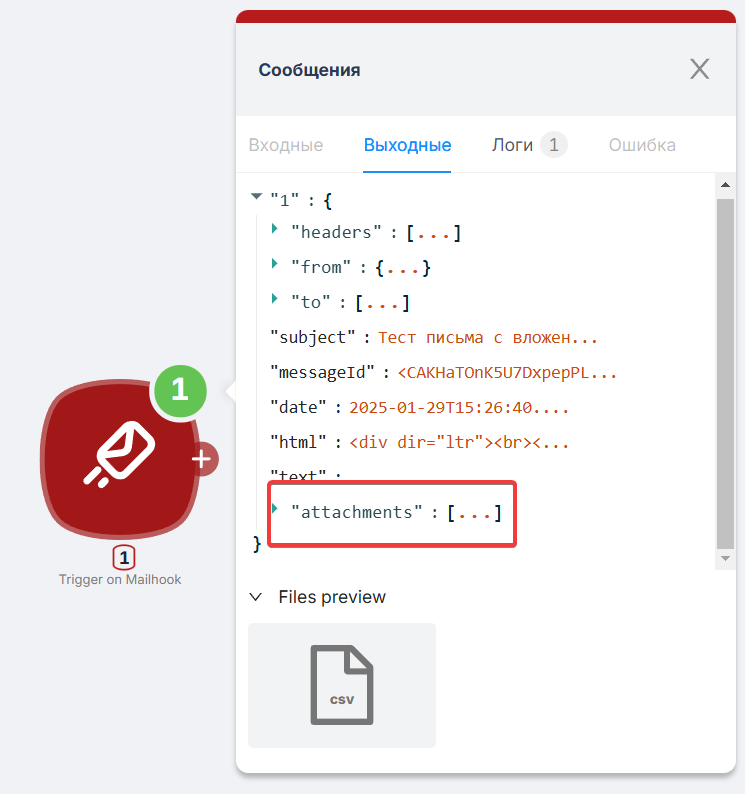
Все вводные данные готовы для дальнейшей работы.
3. Использование файла в последующих узлах
Для примера создадим автоматизацию для сохранения файла на Google Диск.
-
Добавим в рабочее пространство узел “Google Drive — Upload File”, авторизуемся в нем и выберем нужную директорию для сохранения.
-
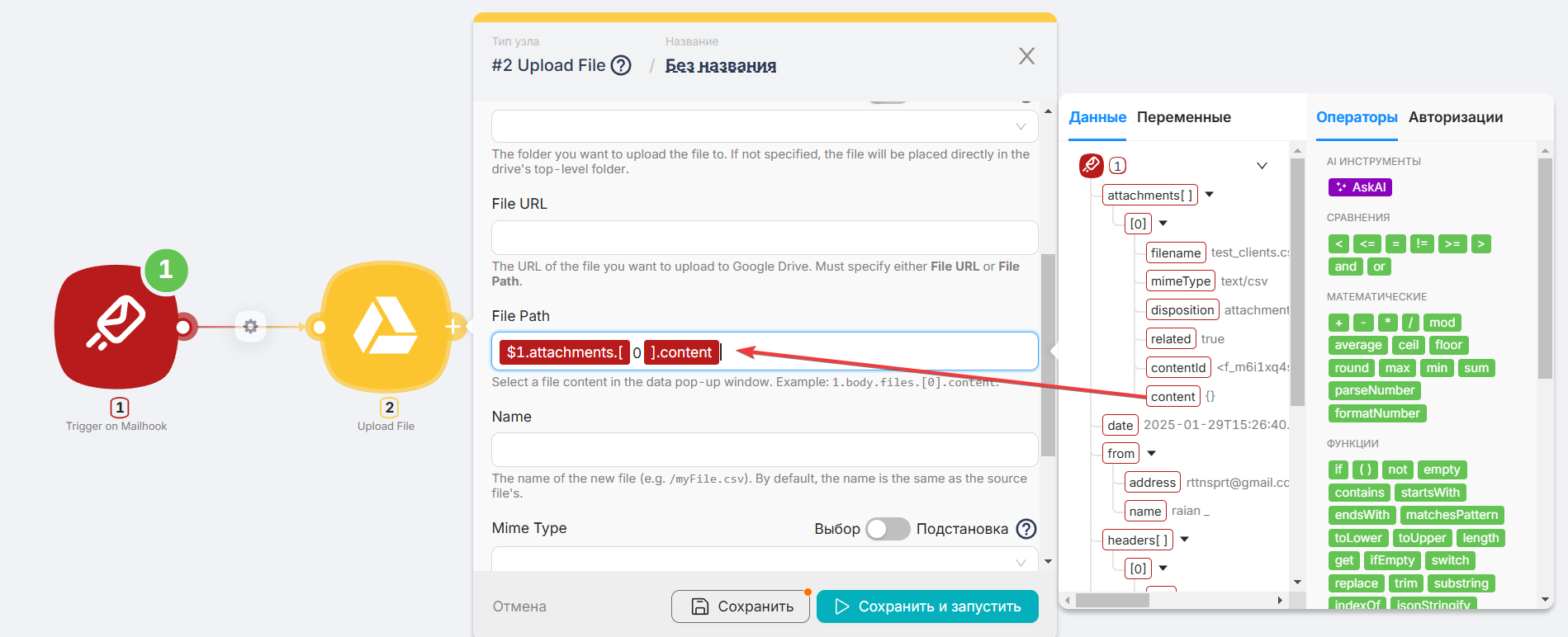
Поместим переменную
contentв поле File Path.
-
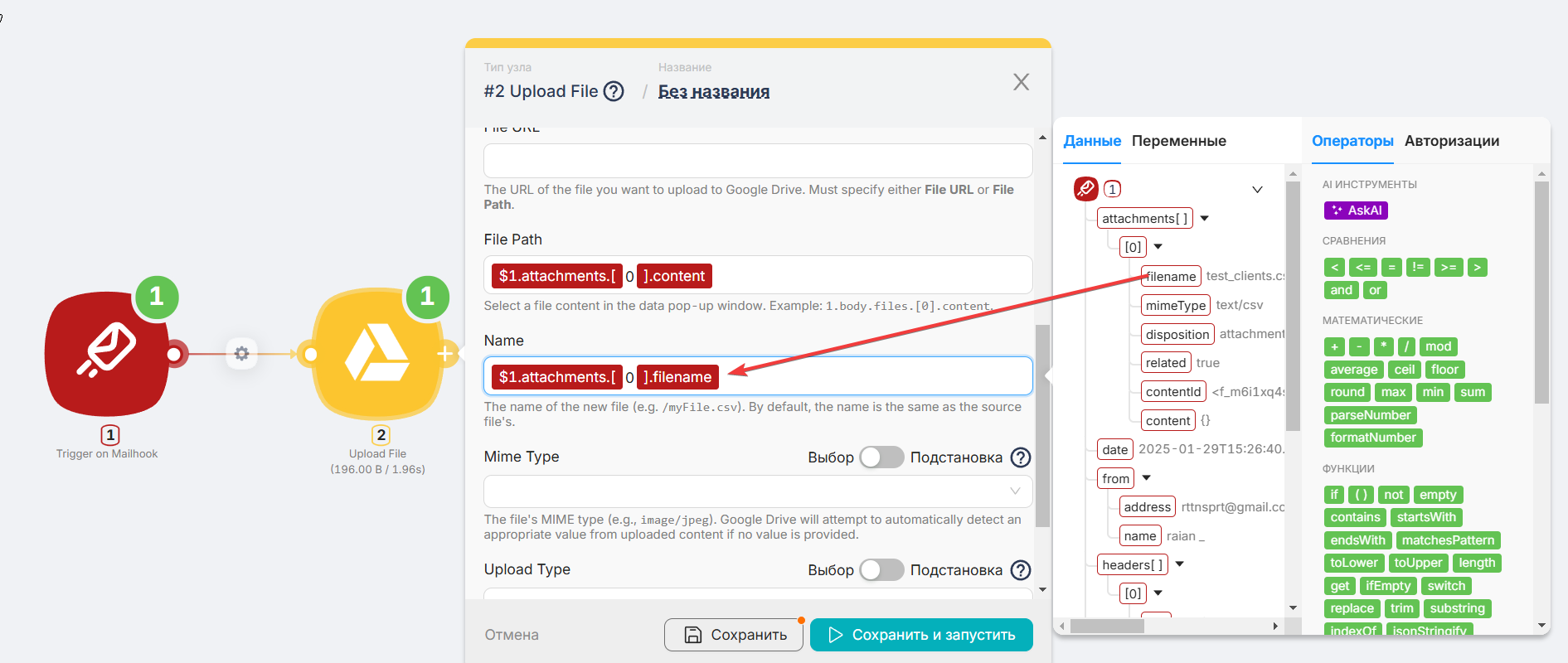
Переменную
filenameпоместим в поле Name.
-
Нажимаем “Сохранить” и запускаем, чтобы проверить, верно ли все настроено.

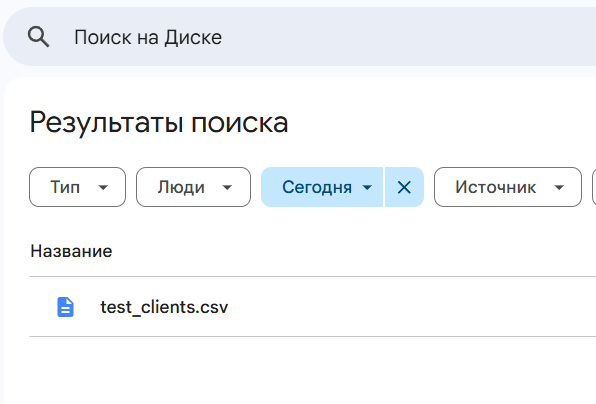
Перейдем в наш Диск и как видим, данные успешно сохранились.
Остается нажать кнопку “Развернуть”, и после этого сценарий готов к автономной работе!
Бонус: Обработка CSV-файлов
Дополнительно рассмотрим пример разбора и записи поступившего на Mailhook CSV-файла.
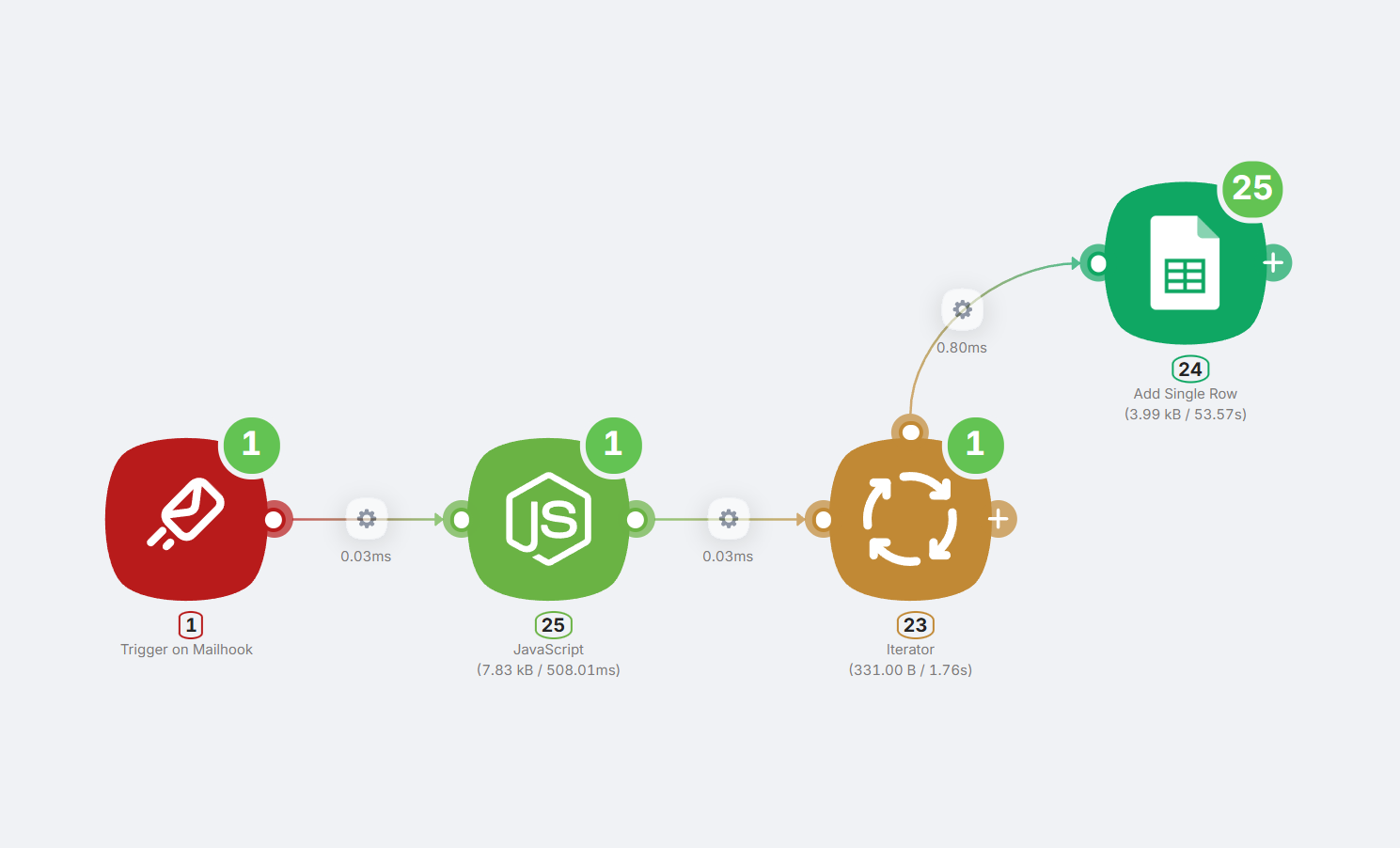
Для этого соберем такую конструкцию:
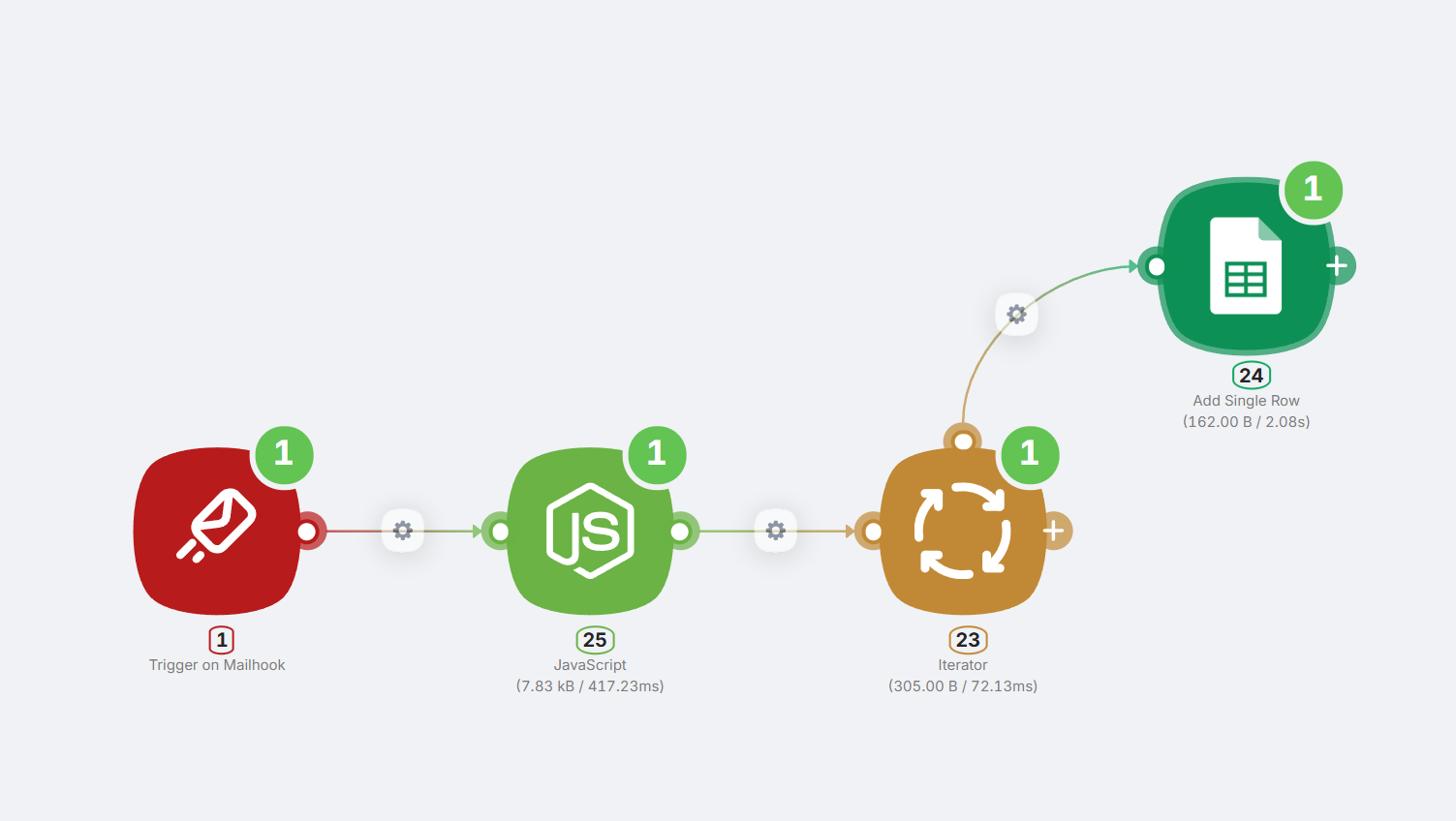
Давайте разберем:
- После узла Mailhook добавляем узел JavaScript и просим его написать код для анализа входящего csv документа, чтобы он вернул его как массив данных.
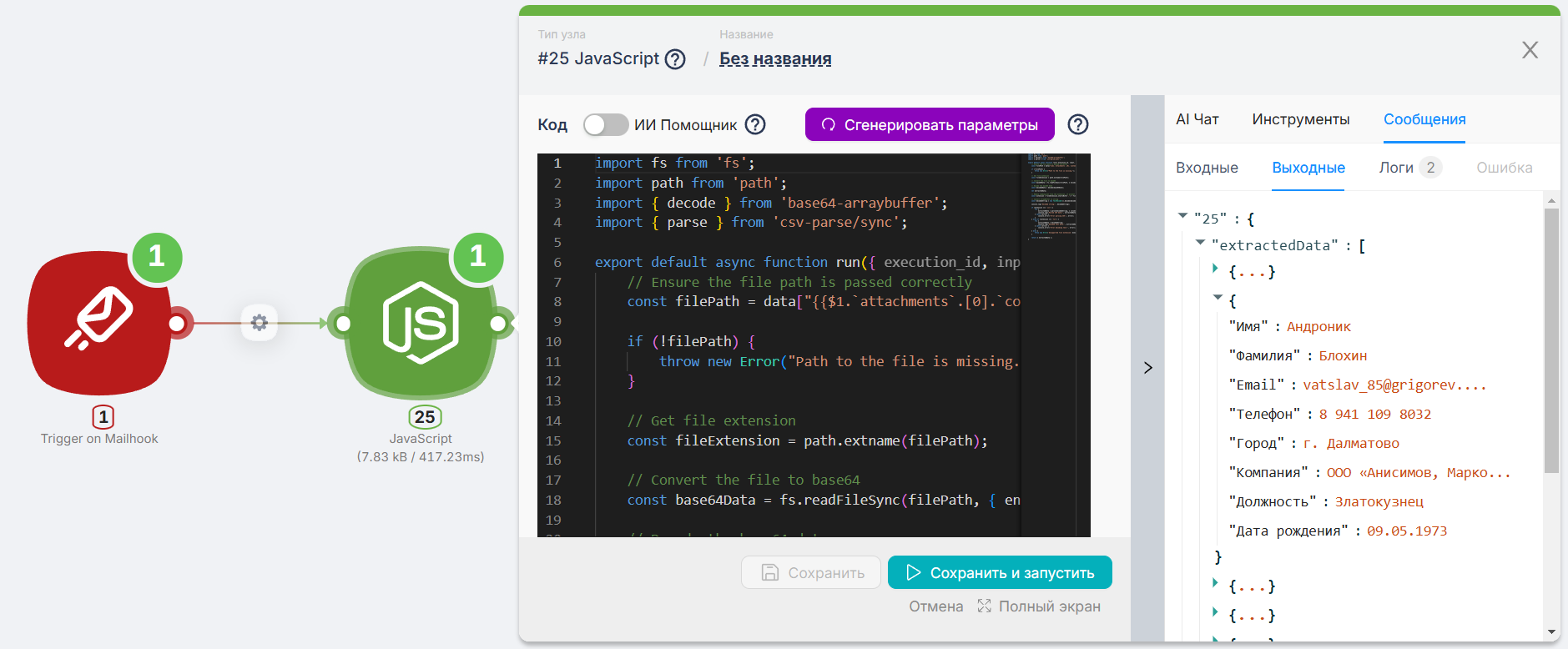
Вот сам код (чтобы вам не пришлось его генерировать самостоятельно, просто скопируйте и вставьте):
import fs from 'fs';
import path from 'path';
import { decode } from 'base64-arraybuffer';
import { parse } from 'csv-parse/sync';
export default async function run({ execution_id, input, data, store }) {
// Проверяем, что путь к файлу передан корректно
const filePath = data["{{$1.`attachments`.[0].`content`}}"];
if (!filePath) {
throw new Error("Path to the file is missing.");
}
// Получаем расширение файла
const fileExtension = path.extname(filePath);
// Конвертируем файл в base64
const base64Data = fs.readFileSync(filePath, { encoding: 'base64' });
// Декодируем данные из base64
const decodedData = decode(base64Data);
let extractedData;
// Убираем точку в начале расширения, если она есть
const extension = fileExtension.startsWith('.') ? fileExtension.slice(1) : fileExtension;
// Конвертируем ArrayBuffer в строку
const decodedString = new TextDecoder().decode(decodedData);
console.log('Decoded string:', decodedString);
if (extension === 'csv') {
try {
extractedData = parse(decodedString, { columns: true });
console.log('Parsed CSV data:', extractedData);
} catch (error) {
console.error('Error parsing CSV:', error);
}
} else if (extension === 'txt') {
try {
extractedData = decodedString;
console.log('Decoded text data:', extractedData);
} catch (error) {
console.error('Error decoding text:', error);
}
} else {
throw new Error(`Unsupported file extension: ${extension}`);
}
return { extractedData };
}
Здесь же можно увидеть пример результата его работы.
-
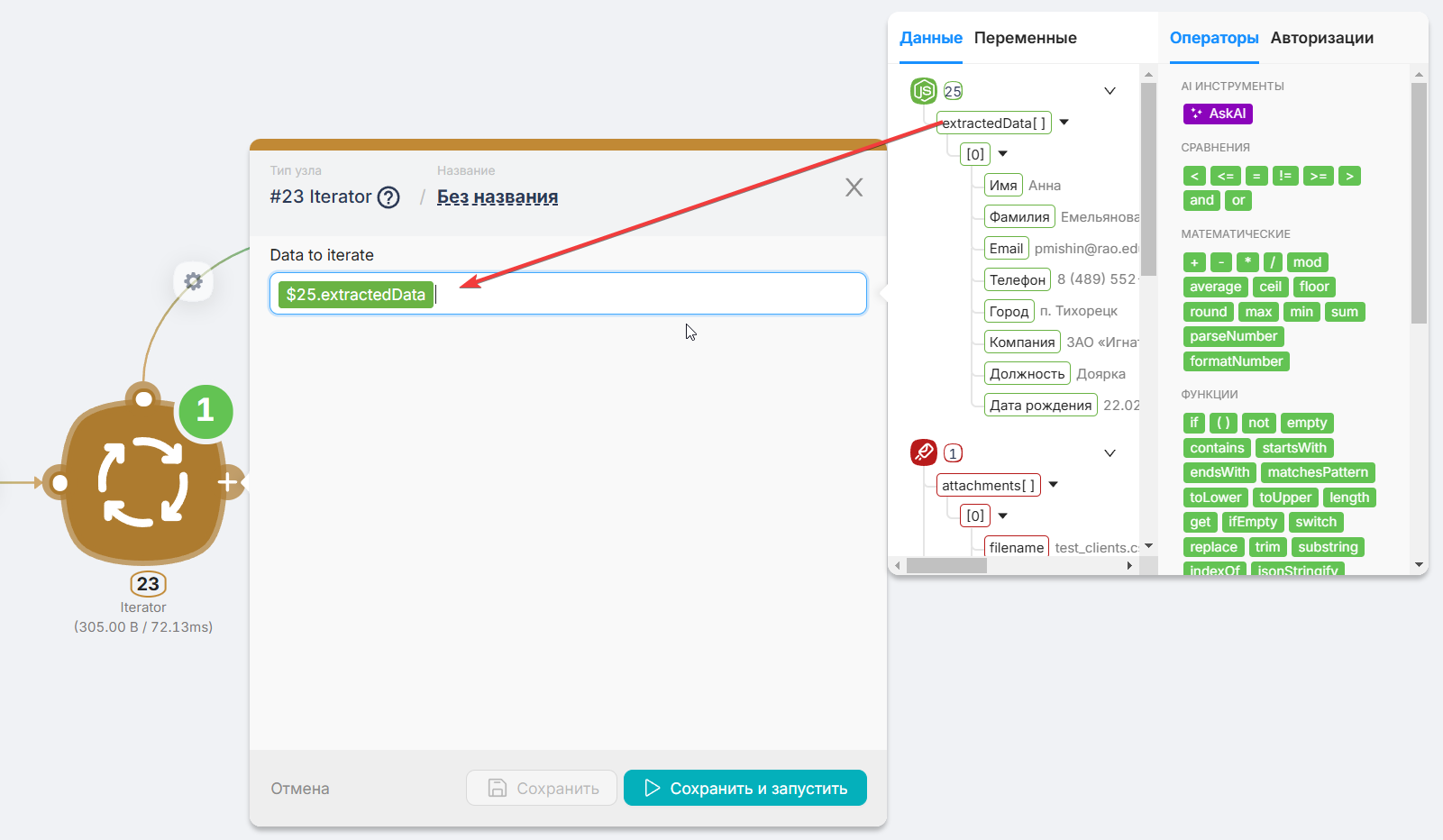
Добавляем узел Итератор, который предназначен для поштучной обработки каждого элемента массива (в данном случае — каждой строки таблицы). Просто выберите переменную с извлеченными данными.
-
В конце добавляем узел Add New Row, который будет записывать каждую строку в нашу таблицу.
Для этого подключите нужную таблицу, выберите пункт “Первая строка в таблице — это заголовки”.
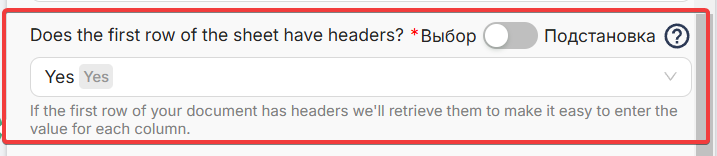
После этого откроются все поля для подстановки с их названиями.
- Подставляем значения из итератора в нужные поля, и все готово!
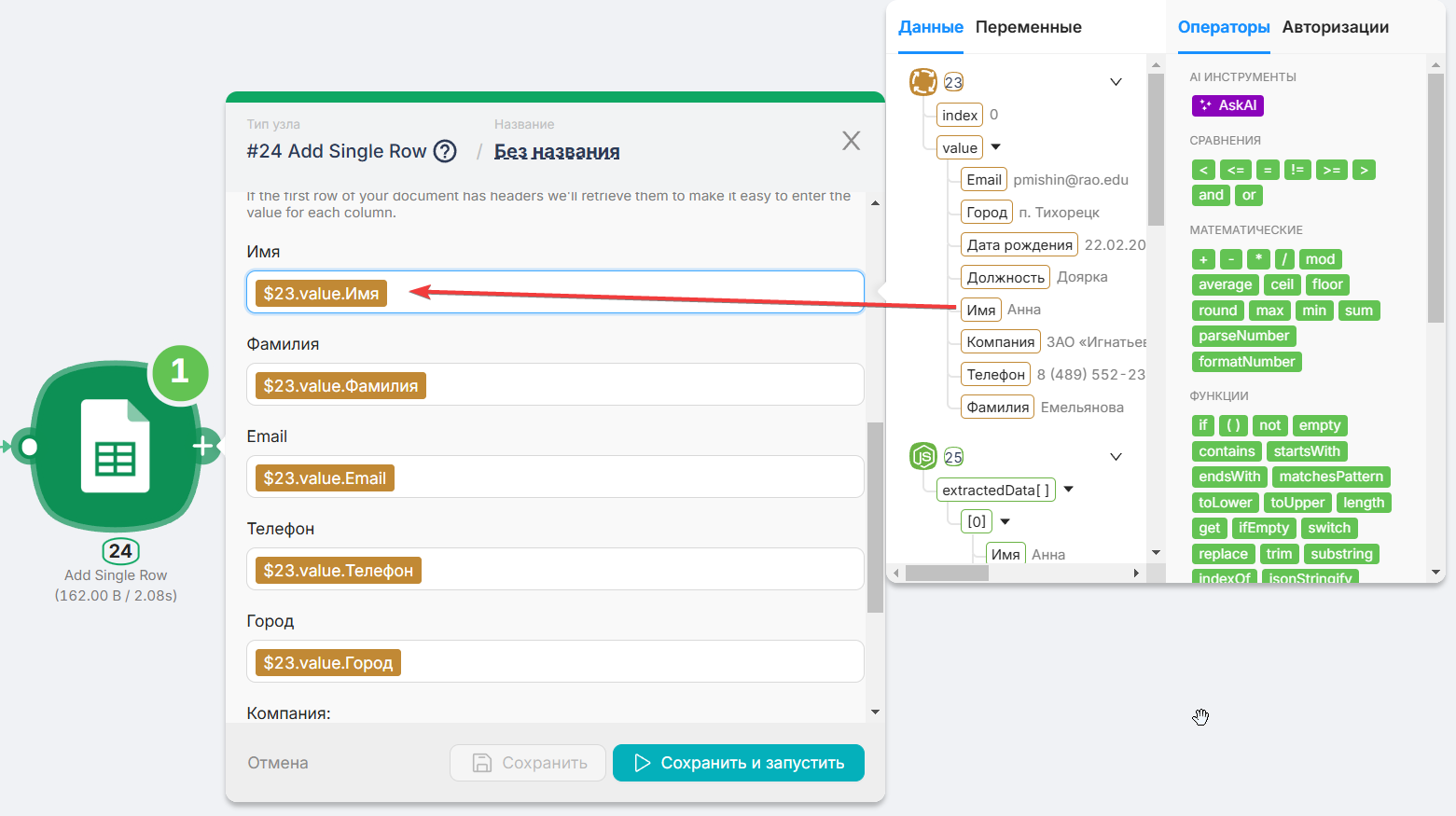
Теперь можно развернуть сценарий и отправить тестовые данные, чтобы посмотреть, как это работает. В результате мы получаем качественно заполненную таблицу с нужными данными.
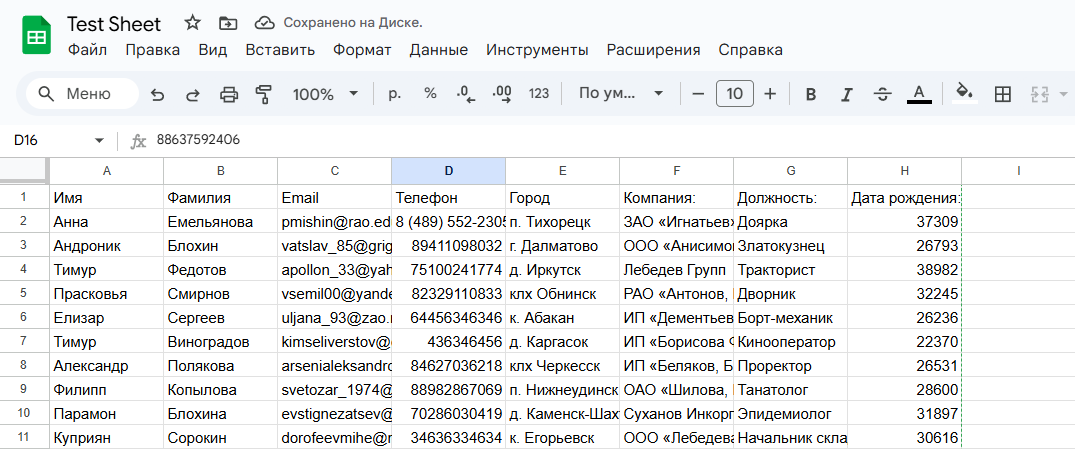
*все данные в таблице являются генеративными и созданы только для примера
Если будут какие-то вопросы, буду рад ответить!